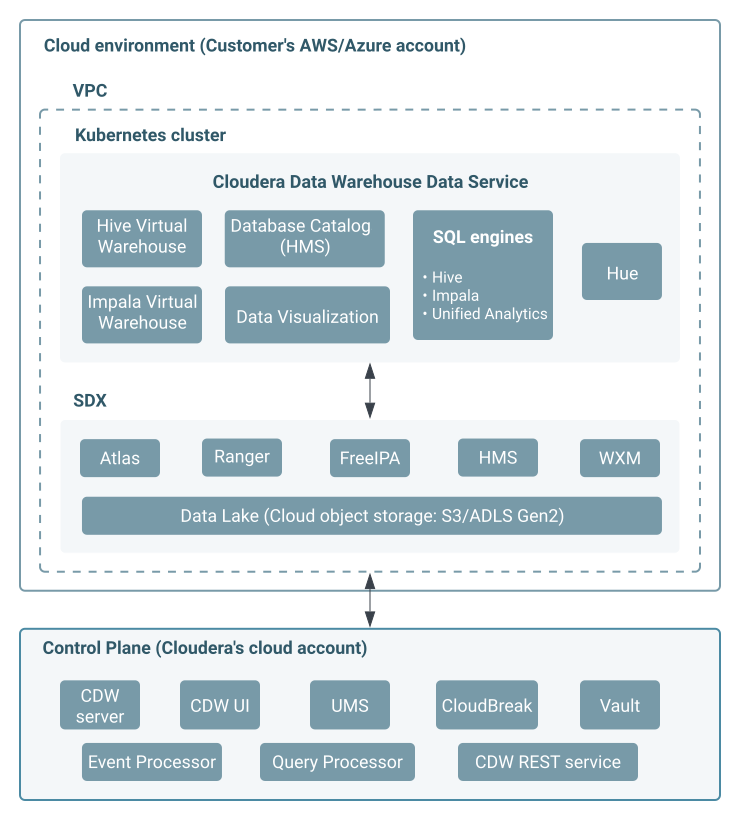
Cloudera Data Warehouse service architecture
Administrators and IT teams can get a high-level view of the Cloudera Data Warehouse service components and how they are integrated within the Cloudera stack.
The Cloudera Data Warehouse service is composed of the Cloudera Data Warehouse Control Plane (CRUD application), Database Catalogs (storage prepared for use with a Virtual Warehouse) and Virtual Warehouses (compute environments that can access a Database Catalog) and they are decoupled by design. Multiple Virtual Warehouses of differing sizes and types can be configured to operate on the same Database Catalog, providing workload diversity and isolation on the same data at the same time. Cloudera Data Warehouse is also integrated with Cloudera Data Visualization for visualizing data and obtaining insights.
Cloudera Data Warehouse Control Plane
The Cloudera Data Warehouse Control Plane is a CRUD application that serves every operation that you can take on the Cloudera Data Warehouse UI or by using the Cloudera CLI. For example, editing a Cloudera Data Warehouse environment, deactivating the environment, upgrading a Virtual Warehouse, suspending (stopping), and resuming (starting or restarting) Cloudera Data Warehouse entities. The Cloudera Data Warehouse Control Plane version is displayed on the bottom left corner of the UI and automatically reflects the latest version when Cloudera publishes a release. For example 1.9.2-b657.
Cloudera Data Warehouse Environment
A Cloudera Data Warehouse Environment is a cluster that is deployed on your cloud infrastructure (AWS or Azure). After you register your environment with Cloudera Management Console, the environment is made available in the Cloudera Data Warehouse service. You must then activate your environment in the Cloudera Data Warehouse service. The Cloudera Data Warehouse environment inherits the version of the Cloudera Data Warehouse Control Plane when it is created.
The Environment version is displayed on the Environments page on the Cloudera Data Warehouse UI. For example, 1.9.2-b657. The Cloudera Data Warehouse Environment version is not automatically upgraded. You must deactivate and reactivate the environment using the backup and restore process to upgrade to the latest version. Reactivating an environment also updates the Kubernetes (AKS or EKS) version.
Database Catalog
A Database Catalog is a logical collection of table and view metadata, security permissions, and other information. Behind each Database Catalog is a Hive metastore (HMS) that collects your definitions about data in cloud storage. An object store in a secure data lake contains all the actual data for your environment. A Database Catalog includes transient user and workload contexts from the Virtual Warehouse and governance artifacts that support functions such as auditing. Multiple Virtual Warehouses can query a Database Catalog. An environment can have multiple Database Catalogs.
When you activate an environment from the Cloudera Data Warehouse, a Database Catalog is created automatically and named after your environment. The environment shares a default HMS with services, such as Cloudera Data Engineering, Cloudera Data Warehouse, Cloudera AI to some extent, and Cloudera Data Hub templates, such as Data Mart. Consequently, the same objects and data sets are accessible from Cloudera Data Warehouse or any Cloudera Data Hub created in the environment by virtue of using the same HMS. Queries and query history saved in the Data Explorer database are stored in the Database Catalog and not deleted when you delete a Virtual Warehouse.
The Database Catalog version is displayed on the Database Catalog Details page. For example, 2024.0.18.1-1. This is the Cloudera Runtime version of the HMS. The Database Catalogs are automatically upgraded when you deactivate and reactivate your Cloudera Data Warehouse Environment. You can also upgrade the Database Catalog independently without reactivating the Environment. Cloudera Data Warehouse displays an Upgrade Now option when a new version is available.
Virtual Warehouses
A Virtual Warehouse is an instance of compute resources running in Kubernetes to execute the queries. From a Virtual Warehouse, you access tables and views of your data in a Database Catalog's Data Lake. Virtual Warehouses bind compute and storage by executing authorized queries on tables and views through the Database Catalog. Virtual Warehouses can scale automatically, and ensure performance even with high concurrency. All JDBC/ODBC compliant tools connect to the virtual warehouse to run queries. Virtual Warehouses also expose HS2-compatible endpoints for CLI tools such as Beeline, Impala-Shell, and Impyla.
The Virtual Warehouse version is displayed on the Virtual Warehouse Details page. For example, 2024.0.18.1-1. This is the Cloudera Runtime version of the underlying SQL engines (Hive, Impala) and Iceberg service that is distributed with a particular release. The automatic or semi-automatic backup and restore procedure recreates the Virtual Warehouses with the latest version however this is not the recommended way to upgrade the Virtual Warehouses. You can upgrade the Virtual Warehouses independently without reactivating the Environment. Cloudera Data Warehouse displays an Upgrade Now option when a new version is available.
Data Visualization
In addition to Database Catalogs and Virtual Warehouses that you use to access your data, Cloudera Runtime integrates Data Visualization for building graphic representations of data, dashboards, and visual applications based on Cloudera Runtime data, or other data sources you connect to. You, and authorized users, can explore data across the entire Cloudera data lifecycle using graphics, such as pie charts and histograms. You can arrange visuals on a dashboard for collaborative analysis.