Run the Cloudera Data Flow function in serverless mode in AWS Lambda
Now that you have developed the NiFi flow and tested locally, registered it as Cloudera Data Flow function in Cloudera Data Flow service, you are ready to run the function in serverless mode using AWS Lambda. For this, you will need to create, configure, test and deploy the function in AWS Lambda.
1. Create the Cloudera Data Flow function
You can use the AWS CLI to create and configure the Cloudera Data Flow function in AWS Lambda.
-
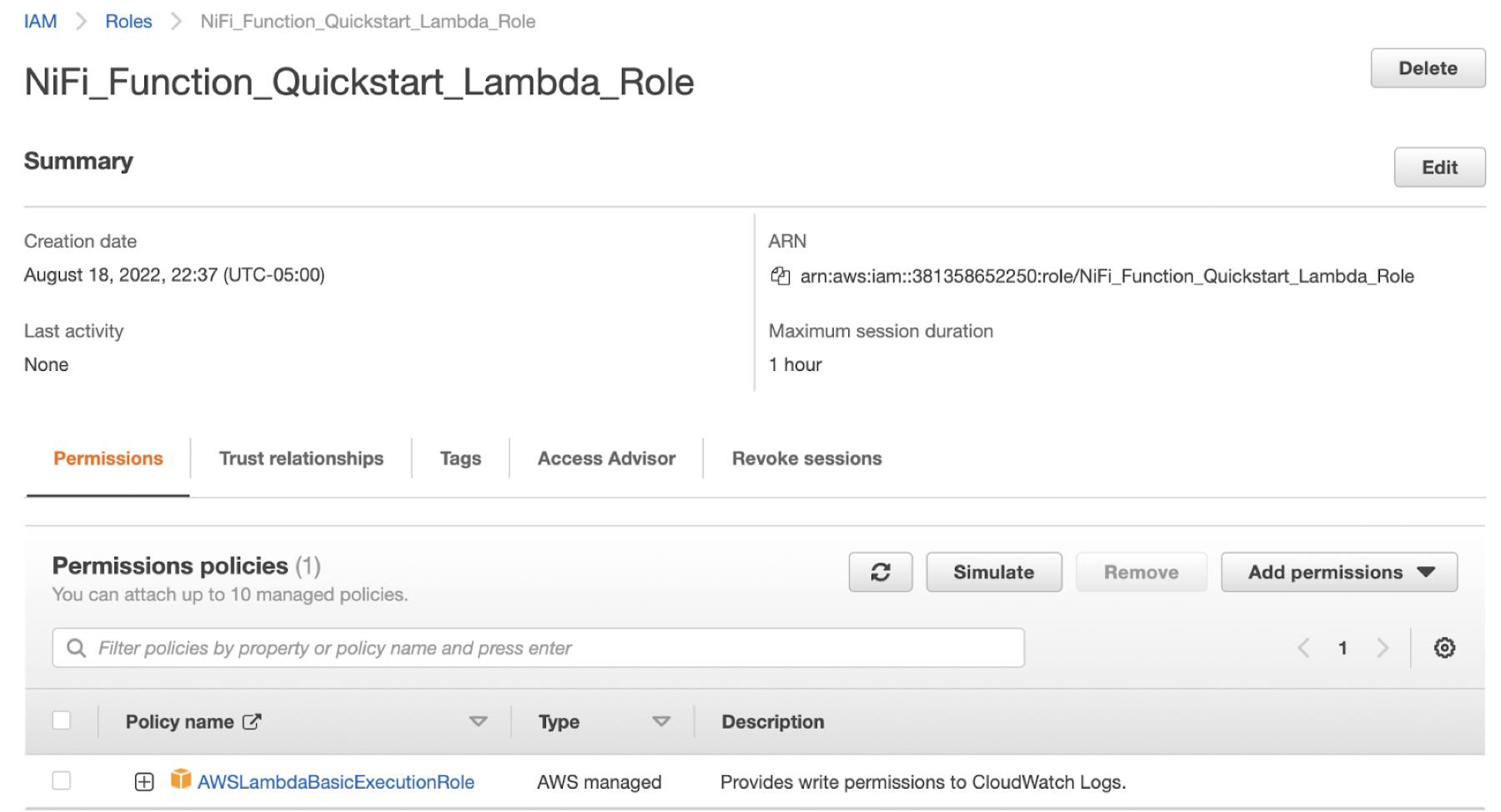
Create the AWS IAM Role required to create the lambda function.
-
These two commands will create the following IAM role. Copy and save the Role ARN
which you will need to create the function.
-
These two commands will create the following IAM role. Copy and save the Role ARN
which you will need to create the function.
-
Create the Cloudera Data Flow function in Lambda.
-
View the Lambda function in AWS Console.
-
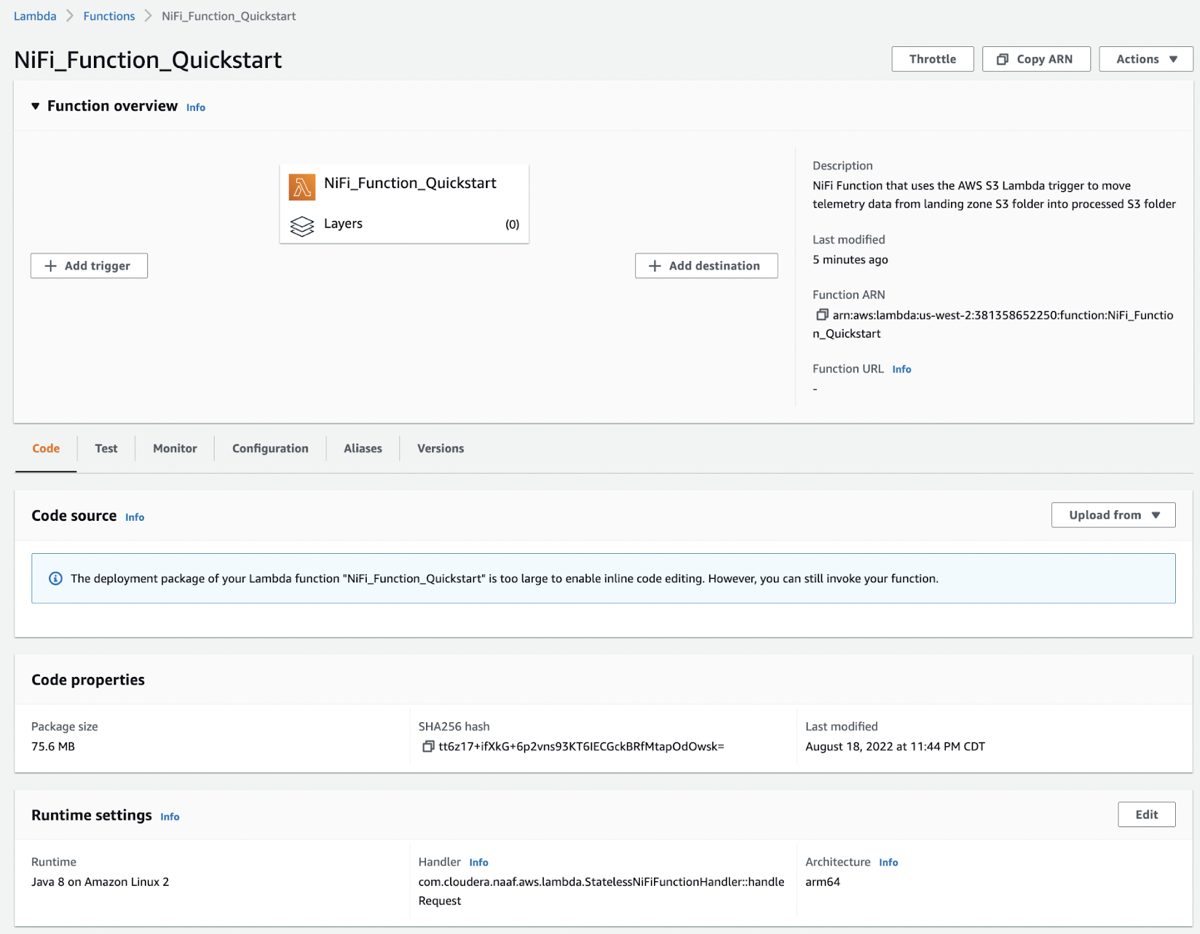
On the AWS console, navigate to the Lambda service and click the function called
NiFi_Function_Quickstart (if the FunctionName property was not modified).
You can see the following under the Code tab of the function:
-
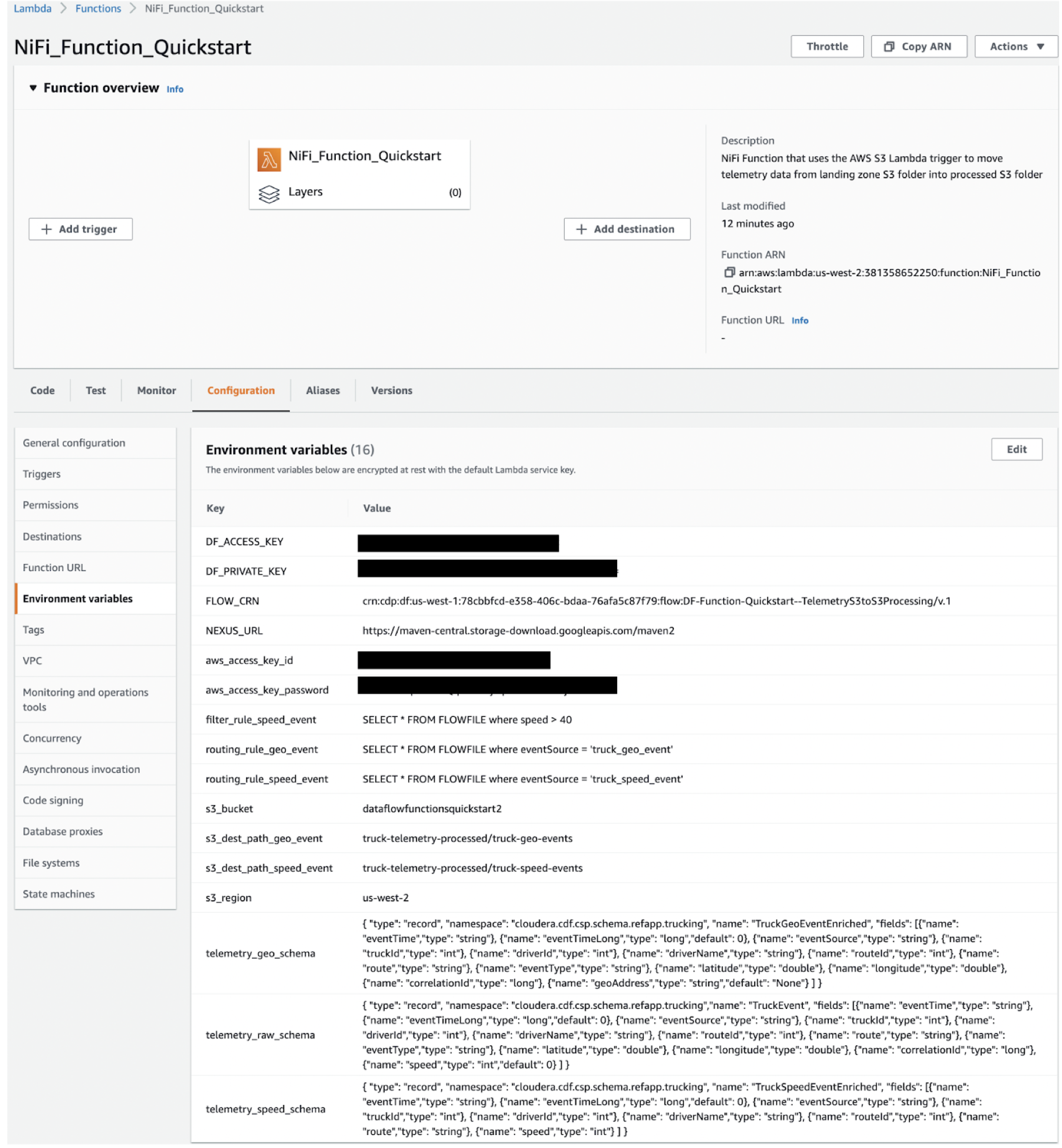
If you click the Configuration tab, you can see all the
configured parameters required to run the function under Environment
variables.
-
On the AWS console, navigate to the Lambda service and click the function called
NiFi_Function_Quickstart (if the FunctionName property was not modified).
2. Test the Cloudera Data Flow function
With the function created and fully configured, you can test the function with a test trigger event before configuring the real trigger in the Lambda service.
-
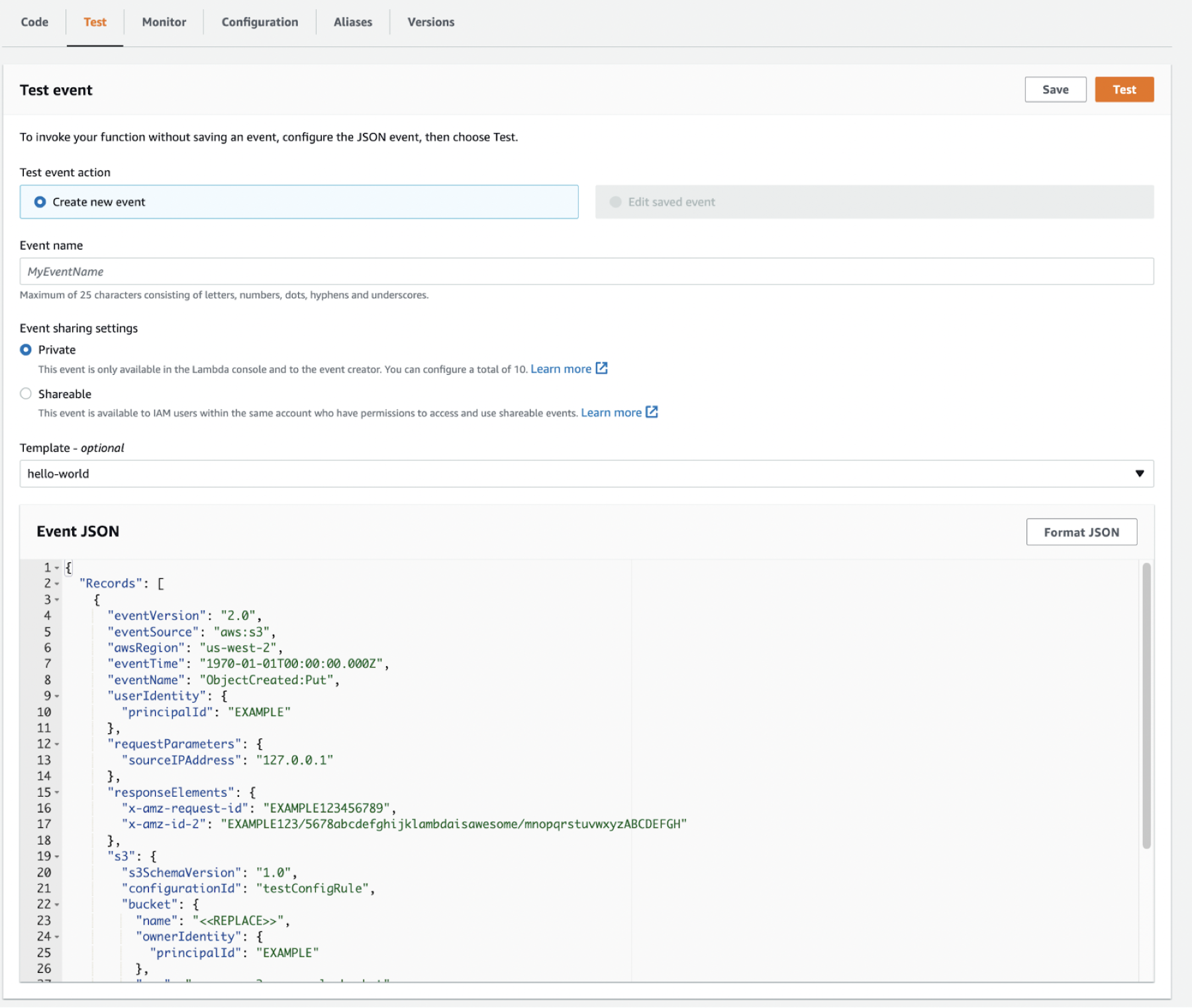
Create a Test Event.
Click the Test tab, select Create New Event, and configure the following:
-
Provide a name for the test: NiFi_Function_Quickstart.
-
Copy the contents from the sampleTriggerEvent and paste it into the Event JSON field.
-
Replace the bucket name with the one you created.
-
Click Save.
-
-
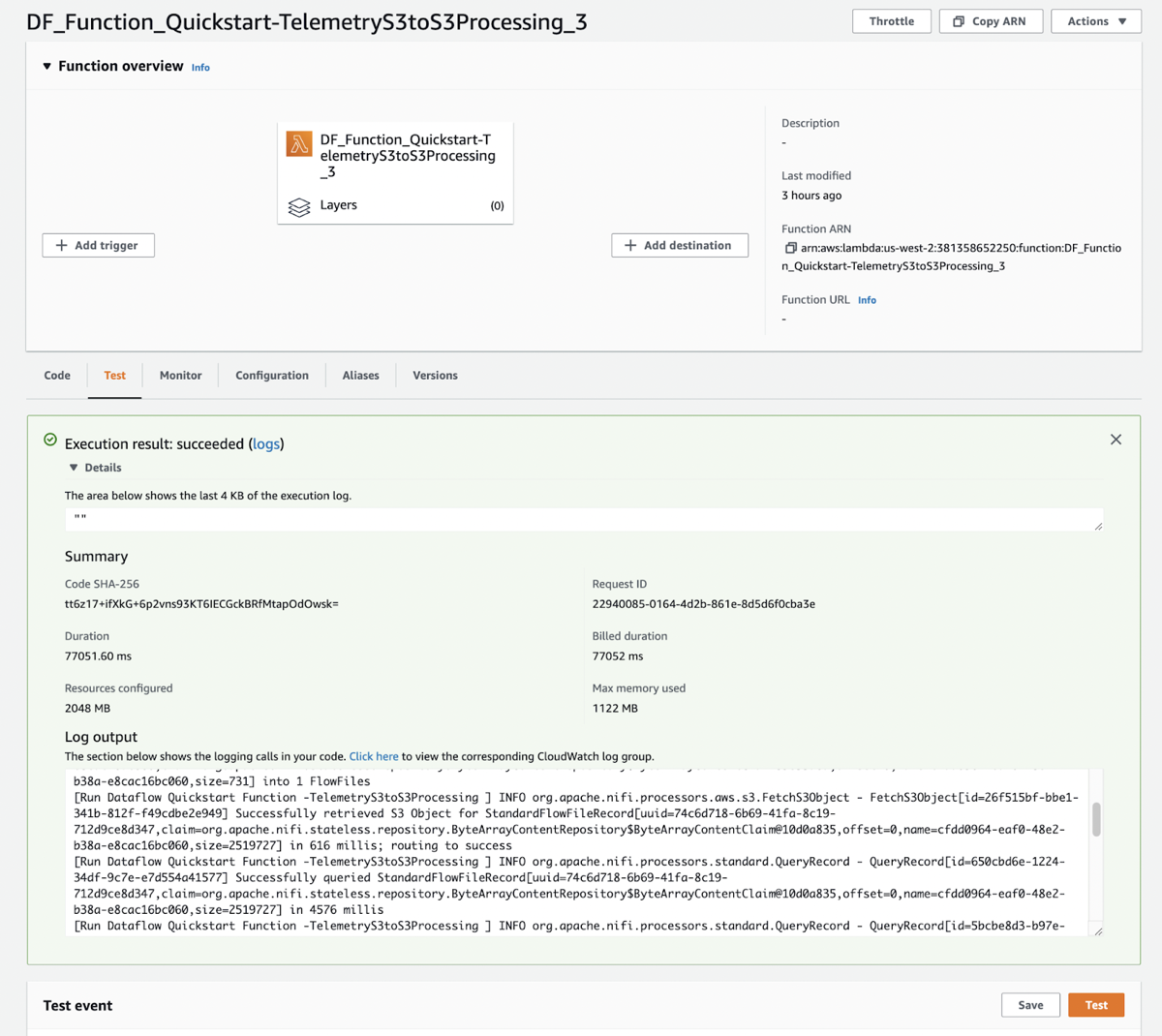
Execute the Test Event.
-
Click Test.
The initial run of the test is a cold start which will take a few minutes because it requires additional binaries to be downloaded from Nexus. Subsequent runs should be faster.If the run is successful, the logs should look like this:
-
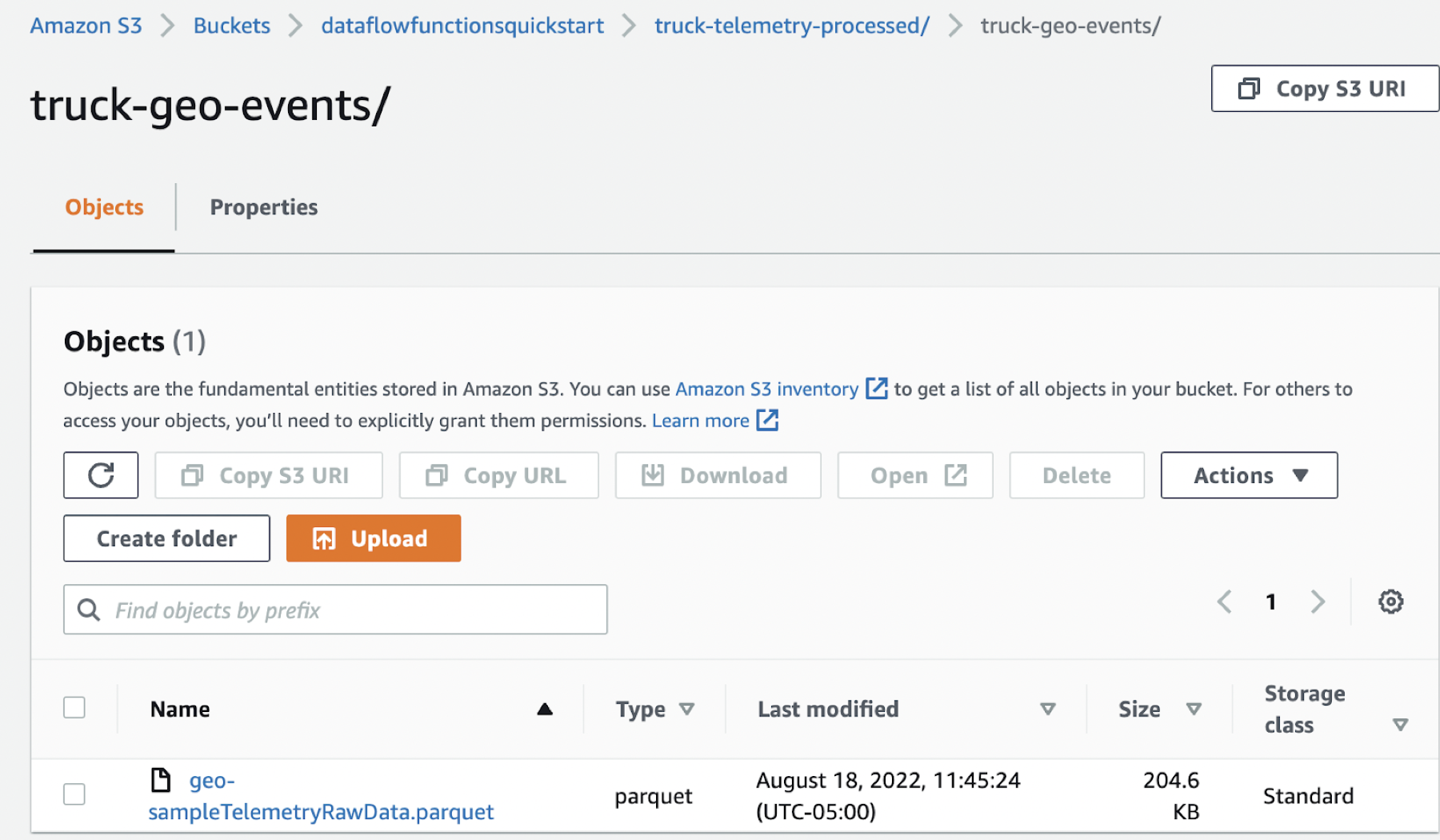
Validate that the processed Parquet files are under the following
directories:
- <<your_bucket>>/processed/truck-geo-events
- <<your_bucket>>/processed/truck-speed-events
-
Click Test.
3. Create S3 trigger for the Cloudera Data Flow function
With the Cloudera Data Flow function fully configured in Lambda and tested using a sample trigger event, you can now create a S3 trigger for the function.
-
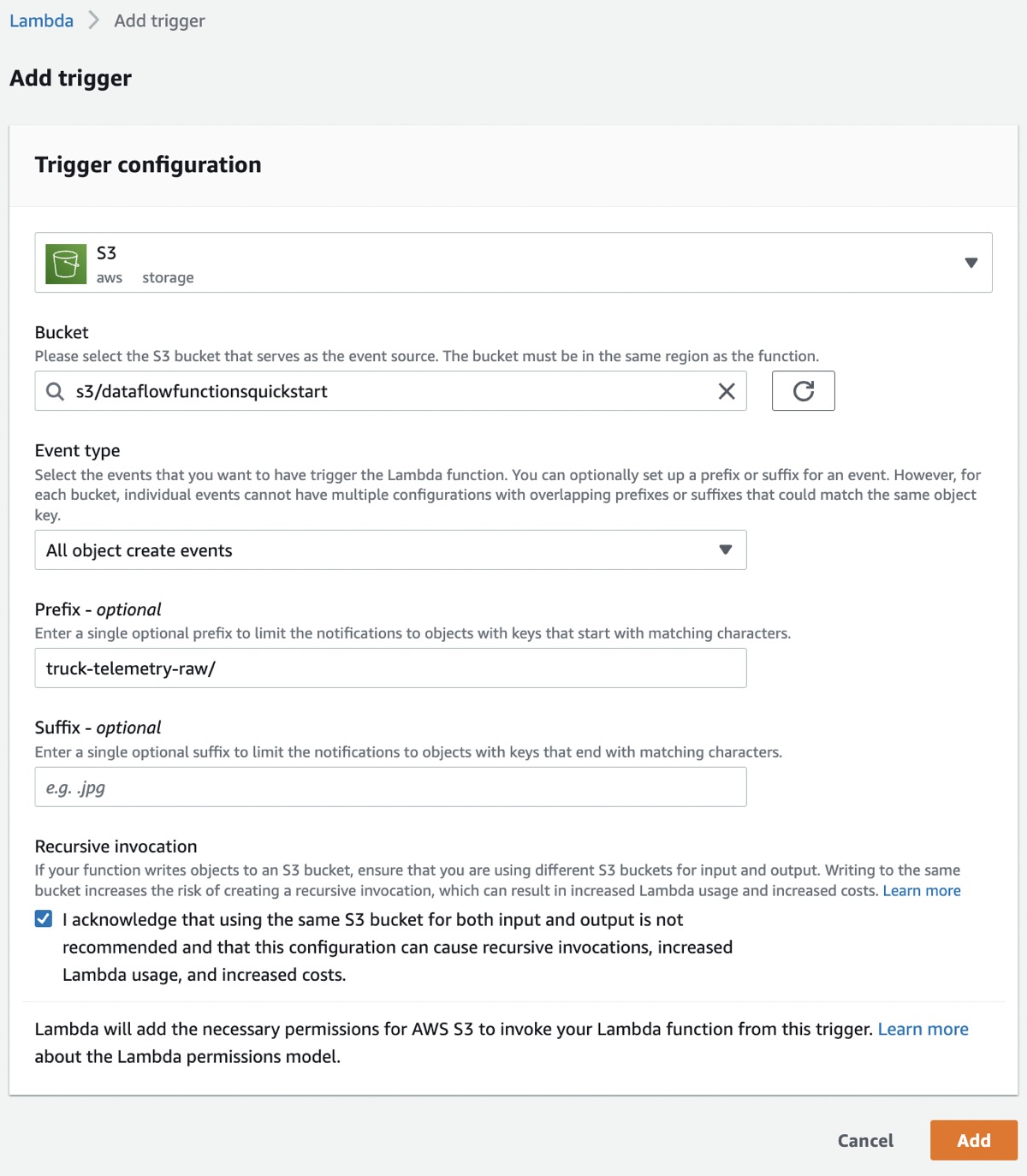
Select S3 as the trigger source and configure the following:
-
Bucket – Select the bucket you created
-
Event type – All object create events
-
Prefix – truck-telemetry-raw/
-
Click the checkbox to acknowledge recursive invocation
-
-
You can test this by uploading the sample telemetry file into
<<your_bucket>>/truck-telemetry-raw.
It will generate a trigger event that spins up the Cloudera Data Flow function which results in the processed files landing in <<your_bucket>>/processed/truck-geo-events and <<your_bucket>>/processed/truck-speed-events.
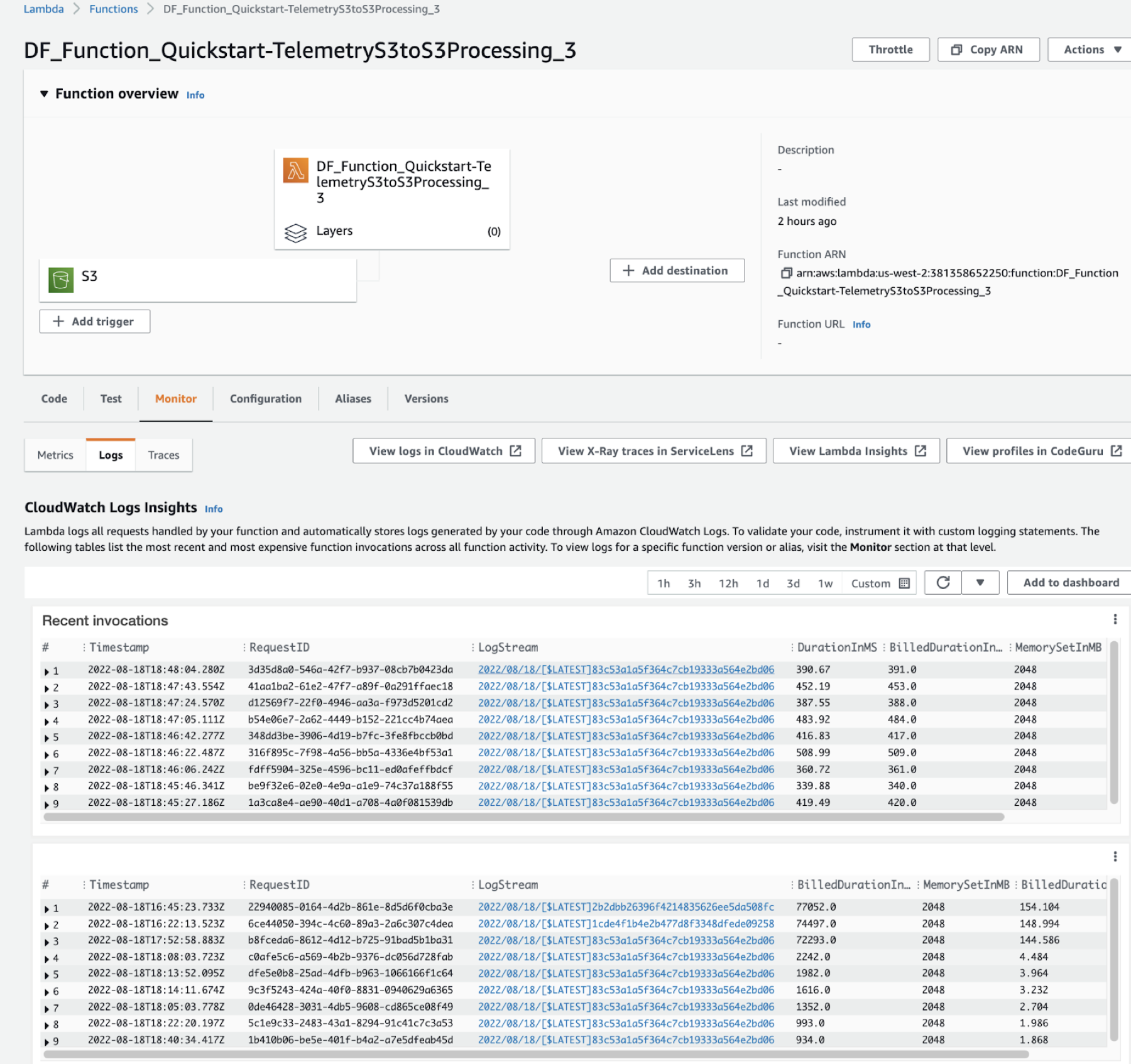
4. Monitor the Cloudera Data Flow function
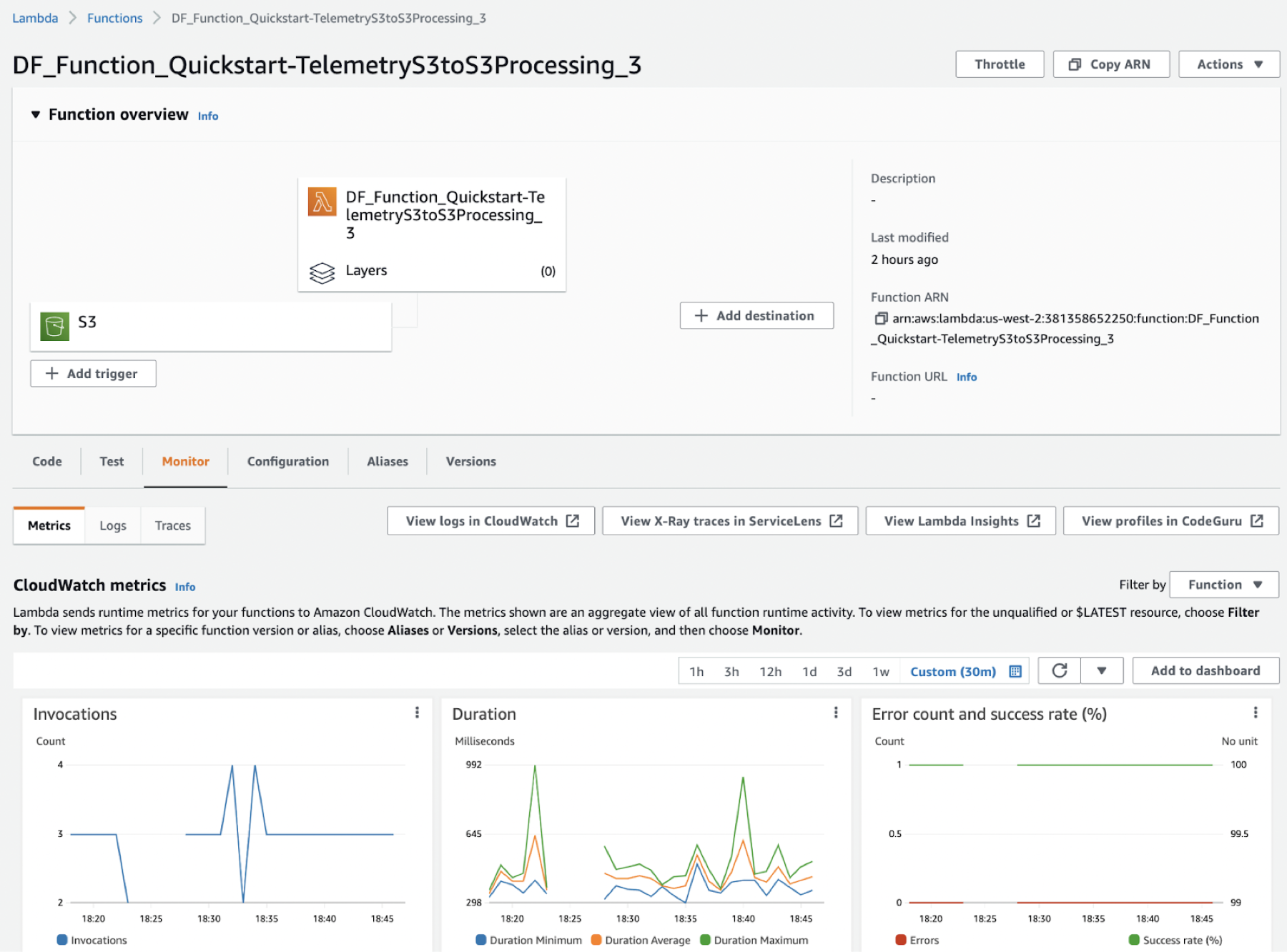
As more telemetry files are added to the landing S3 folder, you can view the metrics and logs of the serverless Cloudera Data Flow Functions in the AWS Lambda monitoring view.
-
If you want to view metrics on all the function invocations, go to the
Monitor tab and select the Metrics
sub-tab.
-
If you want to view all the Cloudera Data Flow function logs for each
function invocation, check out the Logs sub-tab under the
Monitor tab.