Best practices for packaging custom Python processors [Technical Preview]
Depending on complexity and possible shared dependencies, you need to decide whether to create your custom processor as a single file or as a package.
This documentation describes your options on packaging your custom Python processor and making it available for flow deployments in Cloudera Data Flow, and is based on the official Apache NiFi 2 documentation. For additional best practices on writing a custom Python processor for a NiFi 2.x flow, consult the official Apache NiFi documentation. Python processors can be packaged either as a single Python file, or as a Python package.
Single Python File
If the processor is simple and does not share dependencies with any other custom processor, it is easiest to have a single Python file named after the processor, like CreateFlowFile.py. In the single Python file format dependencies are specified directly in the processor.
For example:
class PandaProcessor(FlowFileTransform)
class Java:
implements = ['org.apache.nifi.pythonprocessor.FlowFileTransform']
class ProcessorDetails:
version = '0.0.1-SNAPSHOT',
dependencies = ['pandas', 'numpy==1.20.0']Python package
If more than one custom Python processor uses the same dependencies, or if you have a helper module that you want to use in one or more Python processors, a Python package is required. Structure your code as follows:
my-python-package/
┃
┣━ __init__.py
┃
┣━ ProcessorA.py
┃
┣━ ProcessorB.py
┃
┣━ HelperModule.py
┃
┗━ requirements.txtIn this example, all requirements across the processors and helper modules appear in
requirements.txt, and both ProcessorA and
ProcessorB can reference code in the helper module in a way similar to the
following:
from HelperModule import my_helper_functionWhen uploading a Python package to cloud storage for use in Cloudera Data Flow, add the package directory (my-python-package in this example) directly
inside the cloud storage directory that you are going to specify during deployment.
For example, if you specify s3a://bucket-name/custom-python as your cloud
storage directory in the wizard, the following files should exist in cloud storage:
s3://my-bucket/custom-python/my-python-package/__init__.py
s3://my-bucket/custom-python/my-python-package/ProcessorA.py
s3://my-bucket/custom-python/my-python-package/ProcessorB.py
s3://my-bucket/custom-python/my-python-package/HelperModule.py
s3://my-bucket/custom-python/my-python-package/requirements.txt
Making the processor available for Cloudera Data Flow
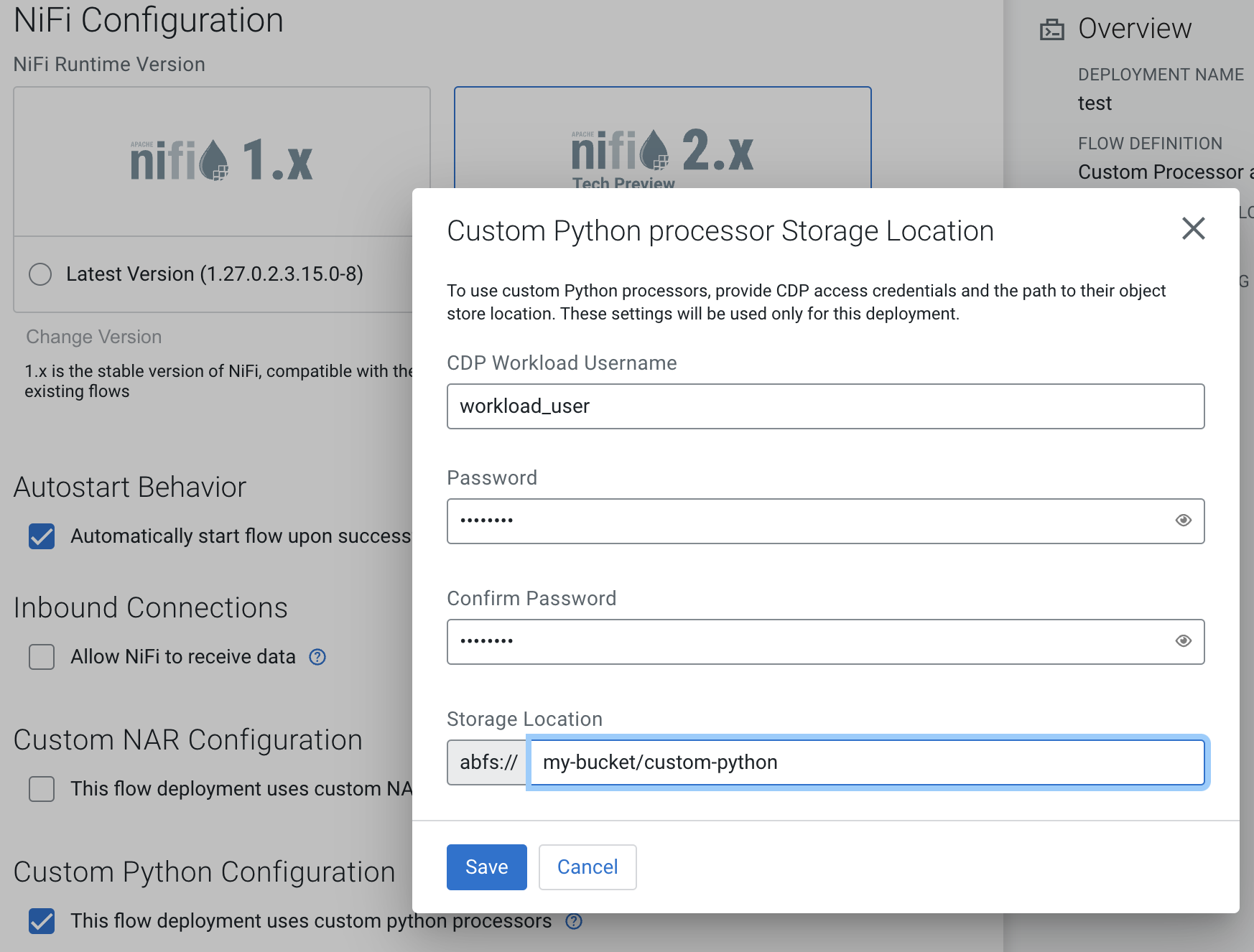
In order to make a custom Python processor available to Cloudera Data Flow, upload it to cloud storage as described in Preparing cloud storage to deploy custom processors.
In the deployment wizard, specify this directory as Custom Python processor Storage Location.