Creating a Cloudera AI data connection to a Hive data
warehouse
Learn how to connect natively to data stored in Hive when using Cloudera Data Visualization in Cloudera AI.
Before you start using data modeling and visualization functions, you must connect to your
data. The following steps show you how to create a new Cloudera AI
data connection in Cloudera Data Visualization to a Hive data warehouse.
When you create a connection, you automatically get privileges to create and manage the
associated datasets. You can also build dashboards and visuals within these datasets.
For more information on the Manage data connections privilege, see RBAC
permissions.
For instructions on how to define privileges for a specific role, see Setting role
privileges.
For instructions on how to assign the administrator role to a user, see Promoting
a user to administrator.
If you are using a Cloudera Private Cloud Base cluster running Hive with Kerberos for
authentication, make sure that Kerberos credentials are configured in Cloudera AI before creating a Cloudera AI data
connection to the Hive data warehouse. This ensures seamless integration and authentication
between Cloudera Data Visualization and the Hive cluster. If you add Kerberos
credentials after launching the Cloudera Data Visualization app, you need to restart
the app for the changes to take effect.
On the main navigation bar, click DATA.
The DATA opens, displaying the Datasets tab.
On the side menu bar, click NEW CONNECTION.
The Create New Data Connection modal window appears.
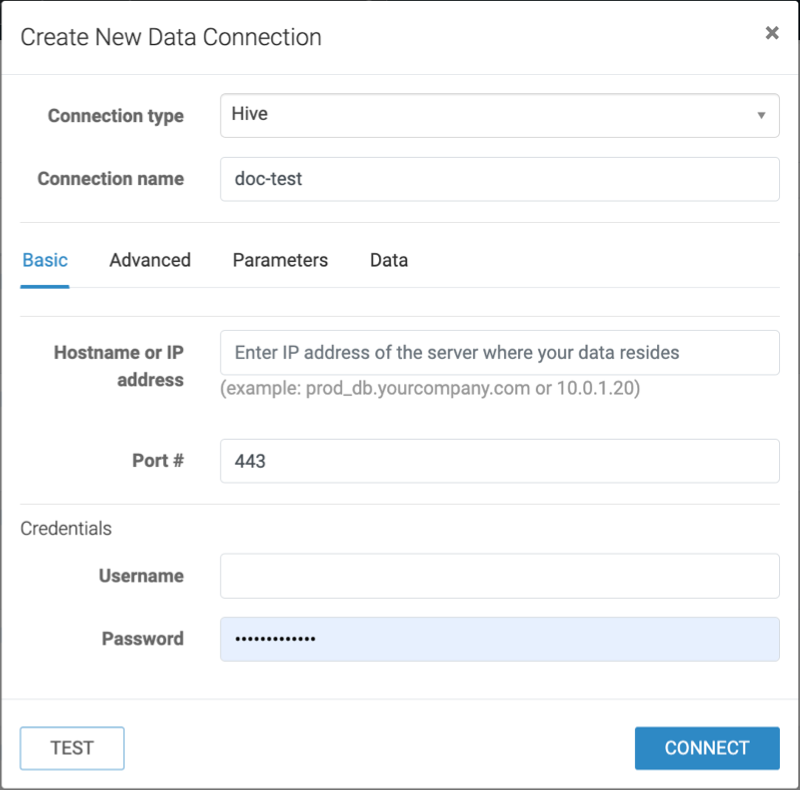
Choose Hive from the Connection type drop-down list and
assign a name to your connection.
Enter the hostname or IP address of the running coordinator.
You can get the coordinator hostname from the JDBC URL of the Hive DW.
Use port 443.
Enter your workload username and password as credentials.
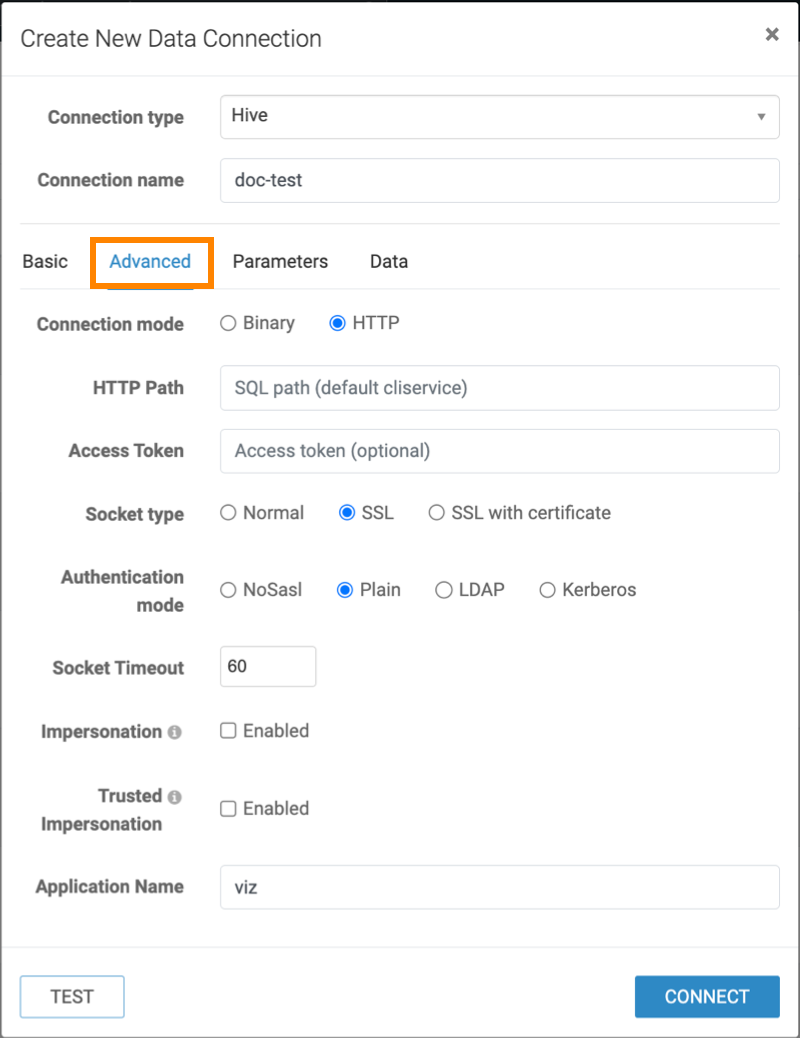
Click the Advanced tab to configure the additional
details.
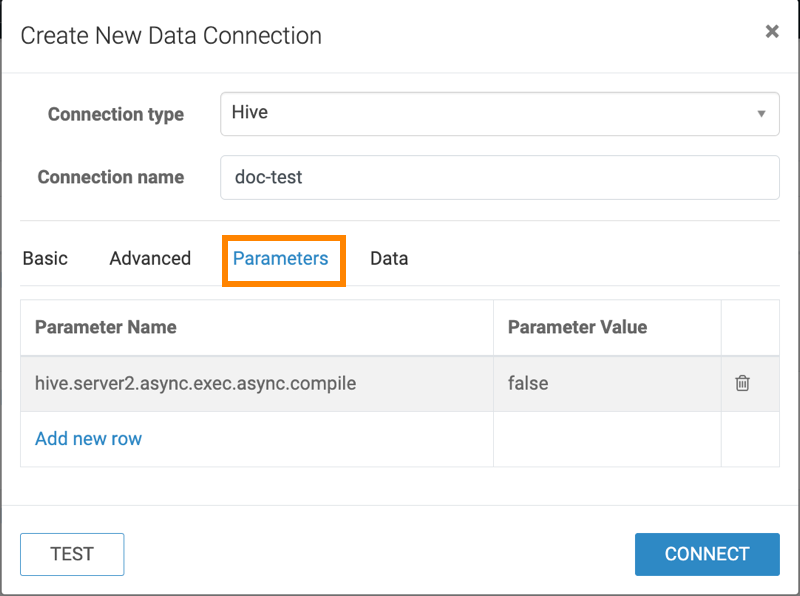
Click the Parameters tab and set the
hive.server2.async.exec.async.compile parameter to
false.
Check the Data tab for more configuration options.
Once you finish configuring the settings, click TEST to test the
connection.
Click CONNECT to establish the connection.
You have successfully set up a connection to a running Hive
DW.
This site uses cookies and related technologies, as described in our privacy policy, for purposes that may include site operation, analytics, enhanced user experience, or advertising. You may choose to consent to our use of these technologies, or