Learn how you can profile your datasets. Dataset profiling provides a high-level
overview of your data, offering insights into structure, content, and quality. This feature
allows you to quickly assess the suitability of your data for analysis, and helps you identify
the appropriate visualizations and any necessary data transformations.
With dataset profiling, you can access detailed statistics for dimension or measure in your
dataset, including data type distributions, missing values, and unique values, as well as
more in-depth information such as column distribution charts and statistics. These insights
help you better understand the quality and characteristics of your data, ensuring it is
suitable for the intended analysis or visualization.
You need to enable the data profiling feature in Site Settings > Data > Enable Data Profiling. For more information, see Managing data related site settings.
Click DATA on the main navigation bar.
The Data view appears, open on the
Datasets tab.
Find the dataset that you want to profile, either by scrolling through the list or
using the search function.
Click the dataset you want to examine.
The dataset side navigation pane opens for the selected dataset, displaying the
Dataset Detail page.
Click Dataset Profiling in the left-side navigation panel.
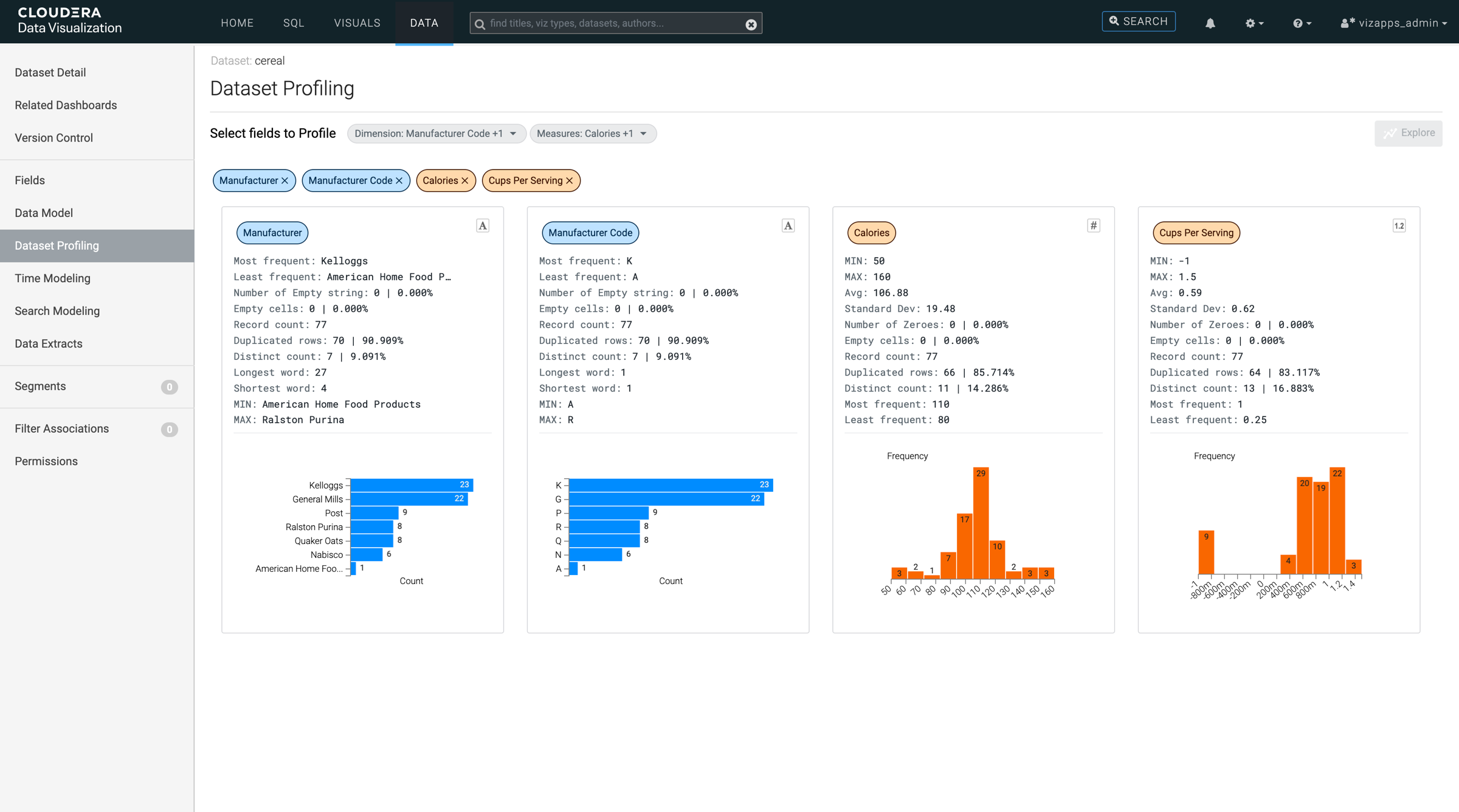
The Dataset Profiling view appears, with the option to select
fields from the dimensions and measures of the dataset.
Select the fields that you want to examine and click
Explore.
Cards with various statistics and visual representations of the selected fields are
displayed. The following information is shown for dimension
values:
Most frequent
The string that appears the most often in the dataset, helping to identify the
most common value.
Least frequent
The string that appears the least often in the dataset, helping to identify rare
or unusual values.
Number of Empty string
The count of cells that contain an empty string, for example
cells that are not null but contain no characters.
Empty cells
The number of cells that are completely empty, including both null values and
empty strings.
Record count
The total number of records in the dataset.
Duplicated rows
The number of rows that are exactly identical, helping to identify redundant data.
A high number of duplicates often signifies low variability in the dataset.
Distinct count
The number of unique values in the dataset, showing how varied the data is.
Longest word
The string with the highest number of characters in the dataset, providing insight
into the potential size of values.
Shortest word
The string with the fewest number of characters, indicating the shortest data
entry.
MIN
The minimum value in the dataset based on alphabetical order, useful for sorting
or range analysis.
MAX
The maximum value in the dataset based on alphabetical order, helping to define
the upper range of the data.
The count histogram for dimensions shows how many times each category appears,
that is the number of occurrences (counts) of each category (dimension). This
visualization is useful for understanding the quality, distribution, and structure of
your dataset.
The following information is shown for
measure values:
MIN
The smallest numeric value in the dataset, showing the lower bound of your
data.
MAX
The largest numeric value in the dataset, showing the upper bound of your
data.
Avg (Average)
The sum of all numeric values divided by the total number of records, giving an
overall sense of the central value.
Standard Dev
Standard deviation that shows how spread out the numbers are in the dataset. A
higher value indicates more variability in the data and a lower value indicates that
the data points are closer to the average.
Number of Zeroes
The count of records where the value is exactly zero, indicating gaps or
null-equivalents in the data.
Empty cells
The number of cells that are completely empty, including both null values and
missing values.
Record count
The total number of records in the dataset.
Duplicated rows
The number of rows where all values are identical, helping to identify redundant
data. A high number of duplicates often signifies low variability in the
dataset.
Distinct count
The number of unique values in the dataset, showing how varied the data is.
Most frequent
The numeric value that appears the most often in the dataset, helping to identify
the most common value.
Least frequent
The numeric value that appears the least often in the dataset, helping to identify
rare or unusual values.
The frequency histogram for measures shows the distribution of numeric values
(measures) within specific ranges (buckets), giving insight into their spread and common
ranges.
This site uses cookies and related technologies, as described in our privacy policy, for purposes that may include site operation, analytics, enhanced user experience, or advertising. You may choose to consent to our use of these technologies, or